Centralhub Search Engine

Website: www.centralhub.com.py
Developer: Nestor Solalinde (manolosolalinde@gmail.com)
A search engine platform for specialized web scraping of local e-commerce sites.
This platform consists of 5 different sub-projects:
-
An E-commerce Search Engine Frontend,
- Project Id: ch_se
- Project website: https://www.centralhub.com.py/
- Description: Search Engine Frontend visible to the public (the final result).
- Technologies: React, Redux, Nextjs, Firebase, Git.
-
E-commerce Search Engine Admin Backend,
- Project Id: chscrapergui
- Project website: https://centralhub-scrape-gui.web.app/
- Description: Search Engine Admin Backend visible to the admin.
- Technologies: Nodejs, React, Redux, Firebase, Github.
-
Web scraping API core and tools,
- Project Id: chscraperapi
- Description: The core scraping module, used to run tests and background tasks using configuration files.
- Technologies: Python, Flask, Docker, NoSQL, Firebase, Google Cloud Platform, Git.
-
Web scraping automation and synchronization tools,
- Project Id: chscraperfunctions
- Description: A set of tools to update databases, synchronize data between different services, and trigger events based on specific conditions.
- Technologies: Nodejs, PubSub, Firebase Functions, Cloud Scheduler, Google Cloud Platform, Git, Task Scheduler, Compute Engine API.
-
Devops, Search Engine Implementation, Architecture, and Integrations.
- Project Id: ch_devops
- Description: A set of documents, scripts, and directives used to set up services, assuring that everything works as expected.
- Technologies: Docker, Pytest, Jest, Firestore, Elasticsearch, Google Cloud Platform.
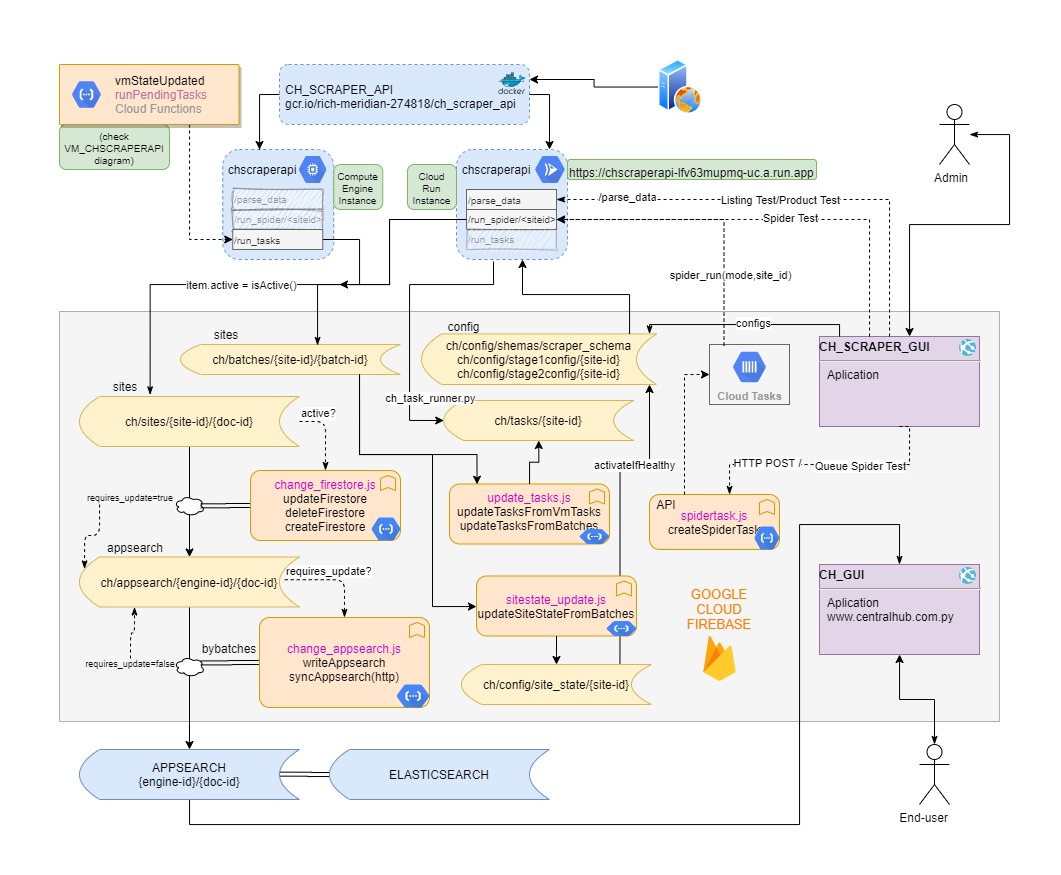
How it works:
-
An administrator uses the admin backend (chscrapergui) to:
- Create, modify or delete configuration files for scraping different sites.
- Test configuration files by calling the web scraping core API tools through HTTP requests (chscraperapi) (running in Cloud Run)
- Enable or disable sites for scraping
- Schedule scraper VM instances to run in the cloud at specific schedules
- Setup configuration parameters for scraping
- Monitor scraping tasks on each site
-
A cloud function (chscraperfunctions) sends an API request to the web scraper (chscraperapi) to:
-
run a set of scripts to scrape the sites and store the results in a NoSQL database (Firestore), according to:
- The configuration of the VM instance, such as the number of threads, schedule, etc.
- The configuration of each site (defined in the admin backend).
-
-
Cloud functions (chscraperfunctions) are used to:
- Automate the behavior of the VM instance that runs the web scraping scripts (turn on or off as required)
- Synchronize the results of the web scraping scripts with the elasticsearch database
- Update the current state of a specific site
- Create scraping tasks according to configuration files
Technologies: Elasticsearch, Python, Flask, Docker, NoSQL, Scrapy, Selenium, Firebase (Functions, Firestore, Authentication, Hosting), Git, JavaScript, React, Redux, Nodejs, Google Cloud Platform (PubSub, Task Scheduler, Compute Engine API, Task Runner, Logging). Testing: Jest, Pytest.
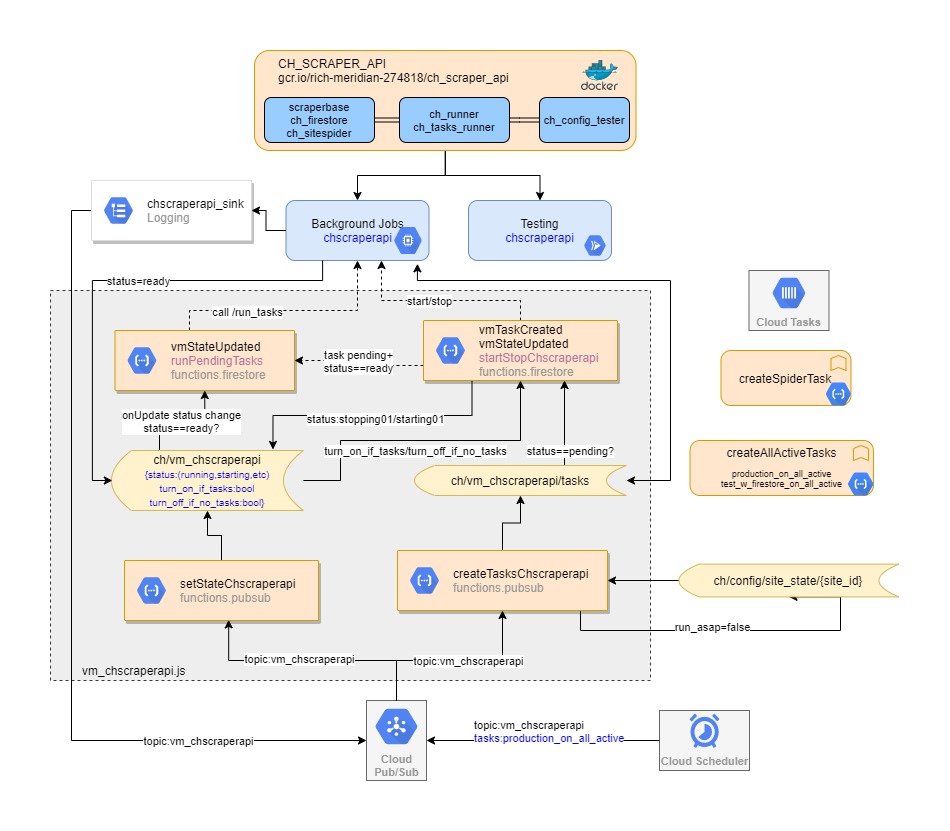
General Architecture:
VM_CHSCRAPERAPI event triggers architecture: